This is part two of a three part series examining the different ways Postgres can fetch rows from a table.
Usually a sequential scan winds up being pretty slow. A sequential scan needs to read the entire table in order to execute the query which can require a large amount of I/O. In many cases, Postgres can instead make use of an index scan in order to read only the portion of the table that is relevant to the query.
Most of the time when people talk about indexes in Postgres, they are referring to b-tree indexes. A b-tree is a kind of search tree that is optimized for databases. When a b-tree index is created, the user enters what column (or columns) the b-tree index should be “on”. For each row, the b-tree contains a leaf node with the column the index is created on and a pointer to the physical row in the table. The internal nodes don’t contain any data themselves and only partition out the child nodes. If we had a people table and created an index on age, the result may look like the following:
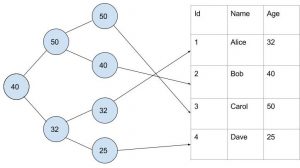
Since the nodes in the b-tree are sorted by the indexed column, Postgres can use the index to speed up the performance of many different queries. There are two main types of types of queries that can be sped up by an index scan.
The first type are queries that contain a filter that is either a range filter or an equality filter on the indexed column. These queries can use an index scan to quickly locate all rows that match the filter. For a range query, Postgres can scan over the relevant portion of the b-tree, looking for all nodes where the indexed column falls into the range specified by the query. Once a node is found, Postgres will fetch the row from the table and add it to the result of the query. As an example the query:
SELECT * FROM people WHERE 30 <= age AND age <= 40;
can scan over all of the index entries where age is between 30 and 40 and fetch only the rows for those entries. A similar search happens for queries with an equality filter.
The other main type of queries sped up are those that sort by the indexed field. Such a query may look like:
SELECT * FROM people ORDER BY age DESC LIMIT 10;
Since an index the is sorted by the indexed field, Postgres can just fetch the rows in the order they are in the index. Although, depending on the exact circumstances, it can be faster for Postgres to perform a sequential scan and sort the rows afterwards. Usually if only a small portion of the table is returned by the query, an index scan will be faster than a sequential scan.
Although indexes are useful because they allow Postgres to perform index scans, there are two main reasons why you wouldn’t want to create the index. First of all, they take up additional space. Since an index contains a complete copy of the column it was created on, if you were to just index every single column on a table, you would find the table was taking up twice as much space as it was before.
Additionally, indexes increase the amount of I/O that has to be performed in order to insert a row into the table. In order to insert a row, Postgres has to write the row into the table, and also insert an entry into each of the table’s indexes.